Policy Gradient vs. Action-value based methods
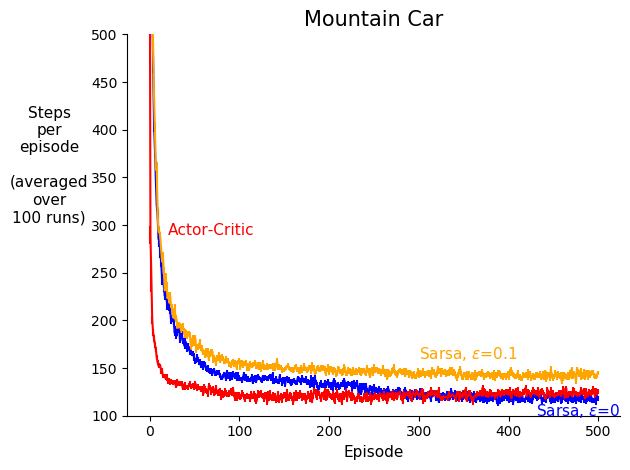
This project analyzes and compares action-value based methods vs. policy gradient methods, in a control problem. The project suggests that policy gradient methods should learn faster than action-value based methods under function approximation. More specifically, one-step Sarsa is compared with one-step actor-critic in the Mountain Car environment, where the empirical results were consistent with the original hypothesis.
Project is part of the RLII course, taught by Richard Sutton in Winter 2020.
Report - Code