Selected Projects
A real-time learning of an off-policy RL control algorithm on a real robot (Create2)
This project applies reinforcement learning algorithms for robotics to learn in real-time. Using an off-policy policy gradient method, we trained an agent that learned how to move the Create2 robot to its docking station. In addition, we investigated the effect of changing one of the sub-goals on the overall behaviour and how it potentially affects the learning process. Our approach outperforms the original implementation in the alignment sub-goal and makes the reward function more interpretable.
Report - Video
A follow-up project presented at RL4RealLife virtual conference, you can find the presentation hereAn empirical analysis on policy-gradient methods vs. action-value based methods for control
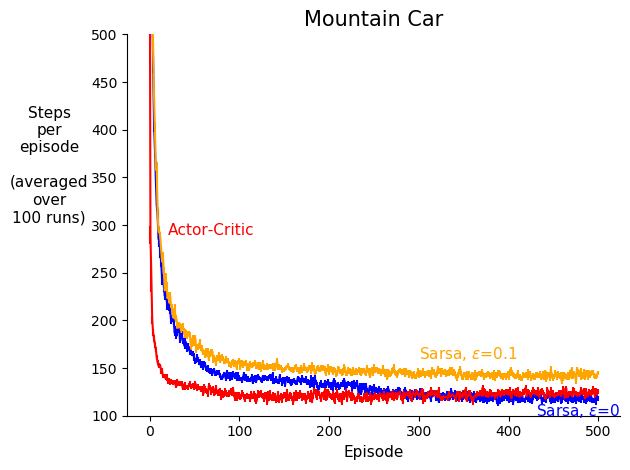
This project analyzes and compares action-value based methods vs. policy gradient methods, in a control problem. Results suggest that policy gradient methods can learn faster than action-value based methods under function approximation. More specifically, one-step Sarsa is compared with one-step actor-critic in the Mountain Car environment, where the empirical results were consistent with the original hypothesis.
Project is part of the RLII course, taught by Richard Sutton, Winter 2020. Report - Code